Purpose
Did you ever wonder or faced the following questions from a customer regarding vRealize Operations Manager?
- Why the resource utilization metrics shown by OS and other monitoring tools does not match with those shown in vRealize Operations Manager?
- Why vRealize Operations Manager shows so many parameters and is complex to look at?
- Why the reclamation suggestions provided by vRealize Operations Manager does not align with other tools?
- Why only badges are shown instead of utilization in vRealize Automation when you integrate it with vRealize Operations Manager?
If your answer is yes to any of the above, then this blog is for you.
Before I go ahead and discuss the above questions, let’s cover some basics first.
What is Monitoring?
Monitoring can be defined as observing the current behavior of any system to make sure that it runs as expected or well within the defined boundaries. We use this method in our everyday life in all possible areas. For this discussion, I am confining myself to only Datacenter monitoring and more specifically to Virtualized Datacenter.
From Datacenter perspective, monitoring means the process of using manual or automated tools and techniques to continuously observe the different components of Datacenter to make sure that the health of every one of them is in compliance with defined criteria’s.
Traditionally from Datacenter perspective we majorly monitor the following components:
- Physical Hardware (Server)
- Network
- Operating System and Applications
- Security
In every datacenter we typically have Network Operations Center (NOC) and Security Operations Center (SOC) where we monitor network and security operations of an Organization. Traditionally we have a live display or Dashboard where we project and continuously monitor these environments.
We have solutions like Cacti, Nagios and players like BMC, CA etc. in this monitoring space.
How monitoring a Virtualized Datacenter is different?
With traditional Datacenter monitoring we were monitoring only the hardware, network, storage, Operating Systems and Applications. But virtualization changed the scenario. It introduced another major and vital component between Servers and the operating systems, which is THE HYPERVISOR. Thus with and without virtualization the troubleshooting and monitoring criteria changes significantly. Functionally the rest of the components remains same (Physical Server, Network, Storage and OS/Applications), but the way resource management is done in Virtualized environment is different from traditional one. Please NOTE, though I said everything is same it is actually not, with Software Defined Network and Storage it is different, but that is the subject of discussion for another time.
Let’s see how it is different in virtual environment. In traditional environment all the resources of a server is dedicated to the running operating system and in turn to the application/applications running inside that operating system (OS). Here, the operating system manages all the physical resources available in the underlying physical hardware.
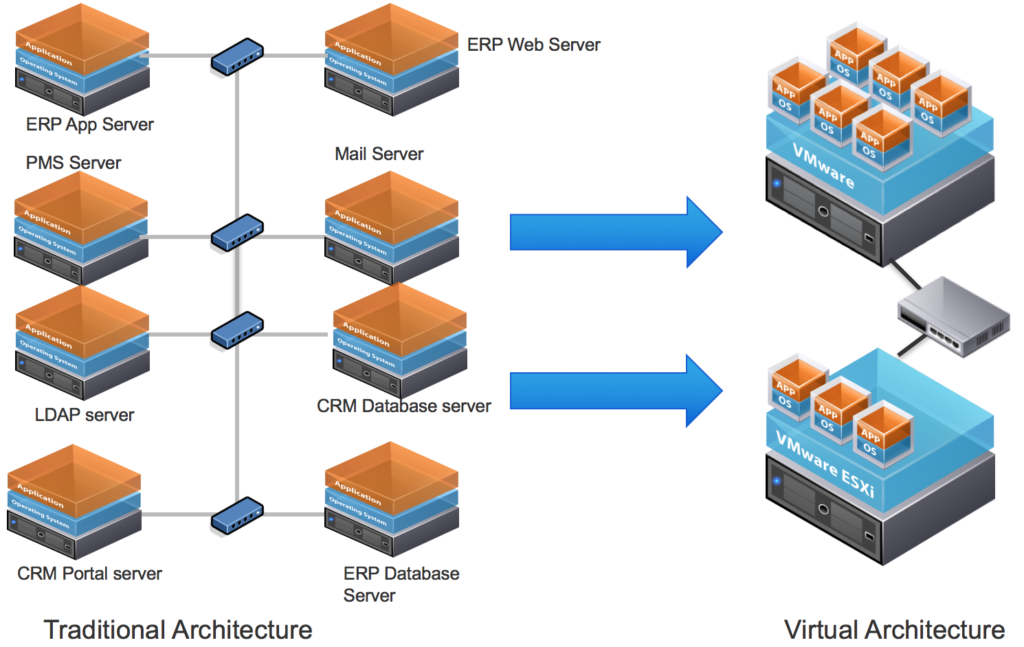
In contrast, in virtualized server, the Hypervisor manages the resources for the virtual machines and thus the resources are shared by many different VM’s and in turn the OS and Applications running inside them. But the entire process is abstracted to the OS running inside the VM. It can see only the resources provided to it by the admin and thinks it has all the resources only for it’s use which is what actually allocated for it. This is not a fact. We are tricking the VM into thinking like this. It is more clear in the following picture.
![vRealize Operations Manager - 1]()
Traditional vs Virtual Architecture
Also troubleshooting in virtualized environment is different because a resource crunch at the hypervisor layer may lead to performance problem in VM. For example, say a virtual machine is using only 50% of all the resources allocated to it, but since there is a storage latency at Hypervisor level, the VM may perform poorly. So now you have another critical layer to monitor for. Actually, I will go so far to say that in Virtualized Environment, Hypervisor perspective is THE MOST important perspective for maintaining performance in that environment.
For obvious reasons, traditional monitoring tools fail to understand or provide the insight required for monitoring a virtualized datacenter. We need more modern, specialized and sophisticated tools for that.
So, traditional tools and way of monitoring is not sufficient for this type of Datacenter.
Next question is what to monitor for? Once you are clear about what you need to monitor then we can decide which tool to use.
What parameters to monitor?
Here I am not going to discuss about physical server, Datacenter Network or Storage health, as that remains same (not considering Software Defined Storage or network). In this blog I am going to talk only about Operating Systems or Applications monitoring. In traditional environment we are content with monitoring different parameters and metrics for server utilization (typically CPU, Memory, Network and Storage). But as discussed above, in virtualized environment what an Operating System sees inside a virtual machine is not the entire picture. It is only part of the picture.
Note: From here onwards I will be more specific to VMware environment, but the general idea and discussion can be applied to any hypervisor environment. It’s just that VMware hypervisor is more sophisticated and has advanced many technologies for managing resources which is not present in other hypervisors.
As a virtualization admin I am more interested about the overall utilization of the physical server. If a VM is under resource constraint (for example, I have given it 4 GB RAM and it requires 6 GB) and I have enough free resources at the hypervisor level, then simply increasing the resources for that VM will solve the problem. But consider the following scenario.
The physical server has 64 GB physical RAM. If I keep aside 4 GB RAM for ESXi Hypervisor, that leaves us with 60 GB RAM.
Next, let’s assume I have deployed 50 VM’s with 3 GB vRAM each in that server. So the total allocation resource is 150 GB vRAM. I am over allocating by 90 GB. Till the time VM’s use less RAM and the overall current requirement stays below 60GB this environment runs fine with no issues. But if somehow all the VM’s starts using 50% of the vRAM allocated to each of them at the same time (you cannot say NO ) then your active RAM requirement is 75 GB which is greater than what the server has (60GB) and you run into performance problem.
You see, all your individual VM’s utilization is 50%, but overall you have severe performance issue.
It is evident that in virtual environment you should monitor not only for allocation or current utilization but also for DEMAND and should be more interested about the TREND than just the current Utilization.
Using normal monitoring tools, monitoring only the current utilization is not sufficient because in virtualized environment you typically over-provision resources (if not memory then always CPU) and you need to know the trend for the resource utilization so that you can predict the utilization as well. This leads to predicting the capacity as well. You need to know well in advance when you will be out of resources and need to procure more. This is particularly important for dynamic environments where the environment grows at a faster pace (service provider or private/public cloud environment).
Also when a problem occurs in a VM, you should be able to see the entire environment from a single page and co-relate between all the different parameters and understand the cause and effect and thus finding Root-Cause of a problem in the shortest time possible.
How vRealize Operations Manager is different?
vRealize Operations Manager does all the above and more. It is not a traditional monitoring tool. It does not even monitor the parameters in real time. It collects the metrics in 5 minute interval and shows the data likewise. So in traditional sense you cannot call it a monitoring tool (in traditional sense a monitoring tool typically monitors the parameters continuously in real-time).
Though many will differ with me, but I prefer to call it an “Analytical and Forensic tool” rather than a simple monitoring tool. You can do monitoring with it, but it’s main beauty lies in the analytical and forensic capabilities. It is a Swiss knife for Datacenter monitoring and analytics.
This tool intimates you about a problem even before it arises. It warns you about the probable issues that may come in near and not so near future. It analyzes and tell you when you will be out of resources. You can run What-If scenarios (what if the utilization increases or a new project comes, when you will need to add more resources).
If any issue arises in your environment, then you can simply click on the notification and drill down to minute details to find out what caused the problem. Actually it automatically does a Root-Cause analysis and gives you probable solutions as well.
With the help of this tool I was able to find root cause of a critical issue in less than 10 minutes with all the evidence I needed, which the traditional infra teams cloud not find in 15 days (a story for a separate time).
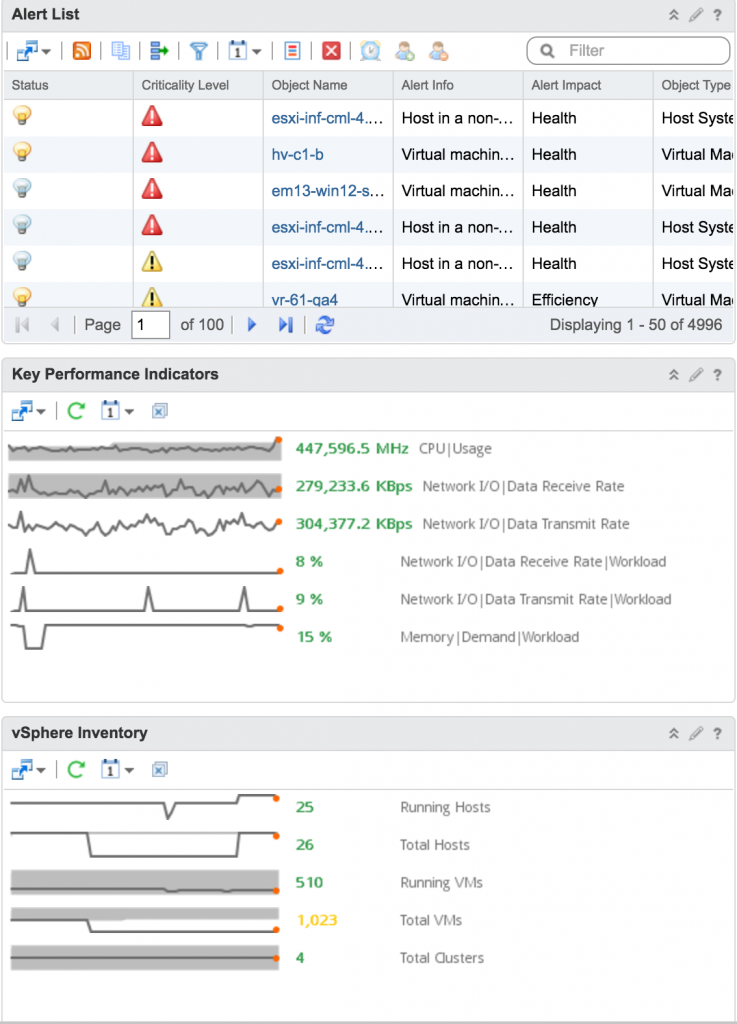
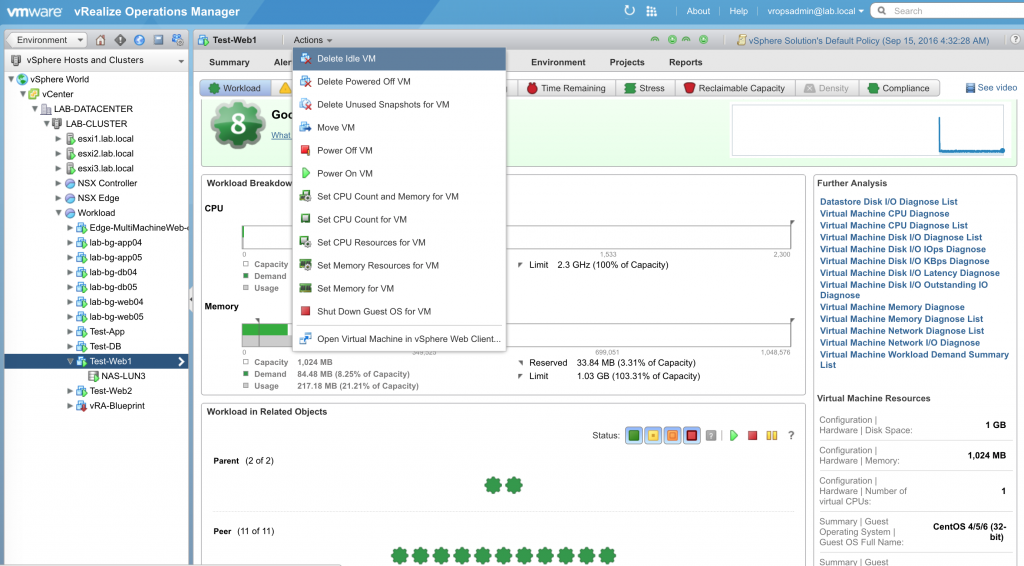
It can show you reclamation values and you can initiate those tasks from this tool. You need to analyze which VM’s taking up most of the resources in the Datacenter? No worries. Same goes for any other parameters. You need to run other analytics on any of the entities? Here you go. Like the Forensic tools and methods you use to find out a security breach, you can apply similar approach to find the root cause of any problem in your datacenter through this tool. Provided below is a screenshot showing what actions you can do on VM’s from this tool.
![vRealize Operations Manager - 2]()
Actions available on the VM’s
It is designed and built to do a lot many things and you should focus on those. If you only want to see the current CPU, Memory, Network, Storage utilization of the VM’s then why do you need this? Any 3rd party traditional monitoring tool can do that. If you want to transform your Datacenter into a modern Datacenter with every bit of it under your control where you already know what is happening and what is going to happen then this is for you.
So you see this is not your traditional monitoring tool. It is way more than that. It is up to you whether you want to use it only to see the current utilization and compare that parameter with other tools or utilize it fully to get the full benefits.
Get your expectations right, learn how to use it, how to interpret the values and this will be the best tool you can have.
Why do the parameters mismatch?
A valid question, most often you see the memory utilization reported by OS or a reporting tool (for e.g, System Center for Microsoft Operating Systems) differ from that of vRealize Operations Manager. Why is that?
You see hypervisor has its own way of managing resources and it looks at the resources differently from that of a typical operating system. A typical operating system looks only at the memory that it is asking for. But hypervisor has different methods. For example, ESXi has four ways of physical memory management.
- Transparent Page Sharing
- Memory Ballooning
- Memory Compression
- Swapping
All of the above helps ESXi to safely give us the option to do over-provisioning of memory. So if a VM asks for new memory pages that does not always mean it is taking extra physical memory space. It may be possible some other VM has the same exact page and that page gets shared with this VM. So essentially this VM got a new page but from ESXi perspective no extra page or memory space is required to serve the request. More about these can be found here.
Hence a new memory request for a VM does not always mean a new memory page served by ESXi.
So from inside the operating system it may be reported that the utilization of that OS instance is 60%, but from vRealize Operations Manager it may report that the utilization of that VM is only 50%. Notice the difference, from inside the VM, OS reports the utilization of the OS, but from outside the VM, vRealize Operations Manager reports the VM utilization which may be different and in all probability will be less than the one reported from within.
Also when you talk about virtualization and memory management by Hypervisor, you need to know the following parameters and what they mean:
- Allocation (Capacity)
- Demand
- Usage
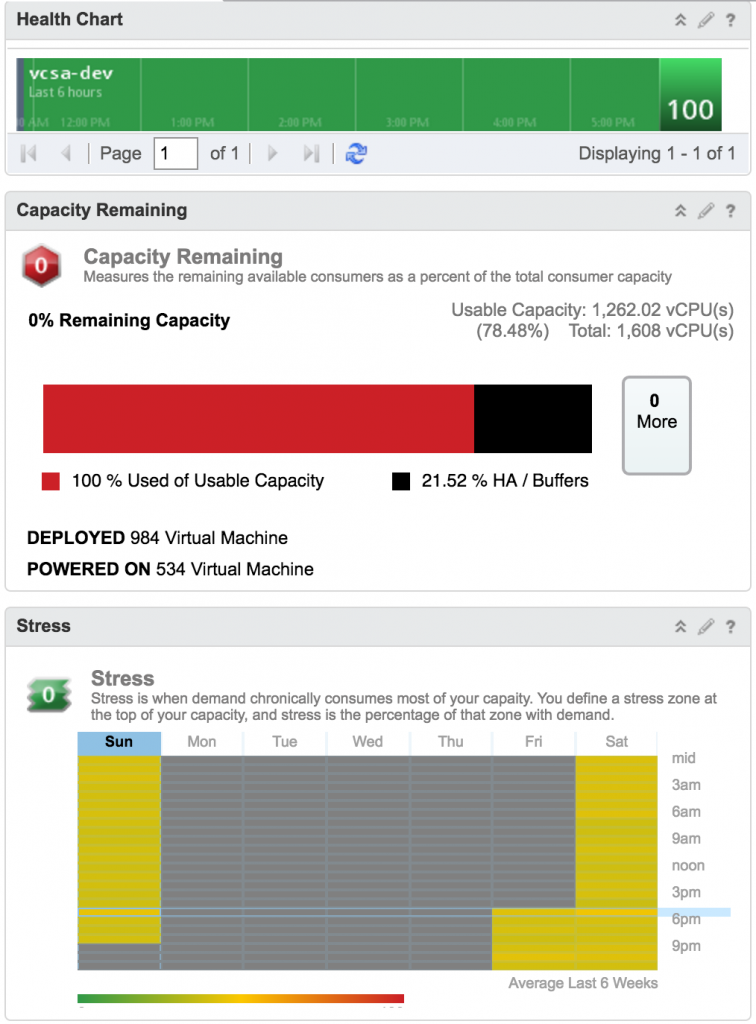
The above three parameters as reported in vRealize Operations Manager.
![vRealize Operations Manager - 3]()
Capacity – Demand – Usage
Capacity (Allocation) means the amount of resources allocated to a VM. In the above picture the VM has a memory capacity of 1 GB. That means while creating the VM, 1 GB vRAM was allocated to it.
Demand, is the amount of resource demanded by the VM at any particular time. In the above picture the VM has a current demand of 84.48 MB.
Usage is the amount of resource provided by underlying hypervisor to the VM. In this case the Usage is 217.18 MB.
In a typical well performing environment Demand should always be less than Allocation and Usage.
If Demand is greater than Allocation, then you have a VM which is undersized. You need to increase resources for that VM.
If Demand is greater than Usage, then you have resource crunch/contention at hypervisor level and you should either increase resources at hypervisor level or decrease number of VM’s running on that hypervisor.
The guest of the VM or generic monitoring tools typically reports capacity and usage parameters.
In the above screenshot you can see considerably higher Usage shown in vRealize Operations Manager whereas Demand is pretty less. This is because, if there is no contention then the amount of memory assigned to a VM is not reclaimed, irrespective of whether the memory pages are active or not. In simple terms, in this case the VM once touched 217.18 MB of it’s allocated 1 GB RAM, since then the Usage is shown as 217.18 MB. Though the current demand (utilization) is 1 GB, but since the memory space was allocated by ESXi server, it is reported as current Usage. If the ESXi host is under resource contention then memory is reclaimed and the Usage goes down.
Since vRealize Operations Manager is an agentless solution and it does not collect generic utilization parameters inside the guest OS, so it has no way of knowing the utilization from Guest OS perspective. The Usage it reports is from Hypervisor perspective. Which is completely different from OS perspective? As explained above a memory requirement from Guest OS perspective does not always covert to a memory requirement from ESXi perspective. This is the reason most of the times you will see that Guest OS or other monitoring tools report higher utilization whereas vRealize Operations Manager reports lower utilization.
When calculating current Capacity or future requirement or suggesting reclamation values vRealize Operations Manager considers Demand and is aggressive in nature. This is the reason you find discrepancy in these values reported in traditional against that of vRealize Operations Manager.
Also note, when deciding whether a VM is idle or over-worked vRealize Operations Manager checks for certain parameters which is set in Policies. The policy is set in the following way:
If a VM’s CPU or Memory utilization is less than 10% for more than 90% of time, then the VM is considered as an idle VM.
Similarly, if a VM’s CPU or Memory utilization is more than 90% for more than 90% of time, then the VM is considered as an overworked VM.
The above values are examples and you can customize the percentage of time and utilization.
What this essentially means is, say in a week if a VM is 10% utilized for 90% of the times then this VM is idle. So essentially, if that VM is 90% utilized for less than 10% of time which is upto 16.8 hours within a week, still it is considered an idle VM. Your typical tool will report the 90% utilization but vRealize Operations Manager will say it is oversized and idle VM. So if the VM had 4 GB RAM, vRealize Operations Manager may recommend for 1 GB. Now if you reduce the RAM to 1 GB then the VM will face severe problem during those 16.8 hours when it requires 3.6 GB of vRAM.
Why only Badges are shown?
I have faced this question multiple times, why only Health badge for a VM is shown in vRealize Automation when you integrate it with vRealize Operations Manager. People expect and want to see realtime CPU and Memory utilization for the workloads.
Please understand what you are asking for is a very nominal thing. What this tool is providing is way beyond that. Knowing only utilization, you need to monitor it, make the decision for yourself. While making that decision at a glance you never know whether it is a intermittent spike or long standing issue. What is the final aim here? To run the application in a healthy state, right? Should you be bothered about the utilization, when the tool is taking care of all of that? It knows what the VM wants and requires and tell you whether it is HEALTHY or not. Whether the spike is well within range or a recurring issue. This is what you should be bothered about. About the state of the VM. This is what you actually want to know and this is what exactly what it shows.
Conclusion:
In conclusion, I can say the following:
- DO NOT COMPARE vRealize Operations Manager with your traditional monitoring tools (set the expectation right). It is NOT A SIMPLE MONITORING SOLUTION.
- While monitoring the VM’s, check and be concerned with the DEMAND of the VM (this is what it requires to run without any performance problems). Based on this change the allocation.
- Check the overall demand and usage for ESXi servers. If Demand goes beyond Usage, then you have a problem in your hand.
- Memory utilization reported by OS of the VM’s or other tools are more accurate than vRealize Operations Manager. As these values are reported from within the VM where they have more insight into the VM. In future releases of vRealize Operations Manager this is going to be more accurate available out-of-the-box (now you need to tweak the default policies).
- Check and double check vRealize Operations Manager policies and tweak it according to your environment, because every environment is different.
- Double check the reclaim values and apply realistically. For e.g if a VM has 12 GB vRAM and vRealize Operations Manager suggests 4 GB, don’t just reduce the value to 4 GB. First reduce the value to 8 GB, monitor for some time and if everything goes well then further reduce to 4 GB.
- While calculating overall capacity of hypervisor trust vRealize Operations Manager. It is based on Demand and is pretty good at predicting the load.
- Change the way you monitor your environment, specially if it a big one. With thousands of VMs you can not monitor utilization for each and every component. With the utilization metrics you need to find the health yourself. This tool gives it out of the box. It learns, knows and tells you about the health of the components. Take advantage of this.
- Go ahead give it a try. Download it from this location.
To know more about this great product please visit the documentation area. Also check the great training available from VMware Education.
Few Use cases
Following are the main reasons for which I use this tool:
- Overall Health Monitoring
- performance analysis
- Troubleshooting and forensic analysis of issues
- Capacity Analysis
- Reporting
Do let me know which features of this product you use. How it helps in making your life easy.
The post vRealize Operations Manager – Monitoring vs Forensic appeared first on VMware Cloud Management.

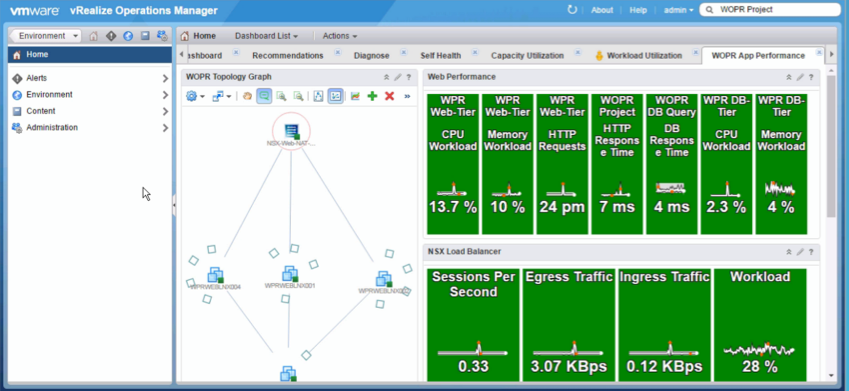

















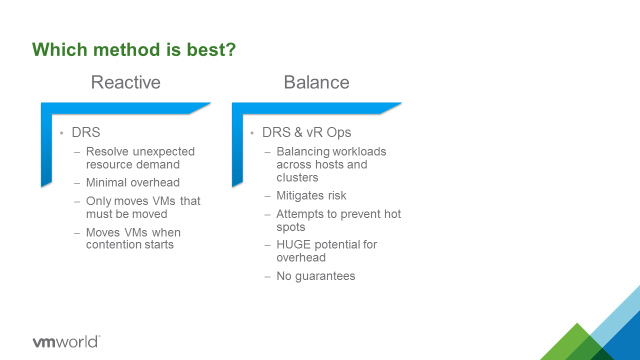
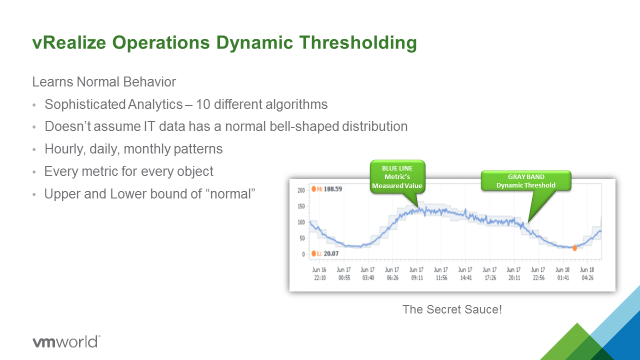
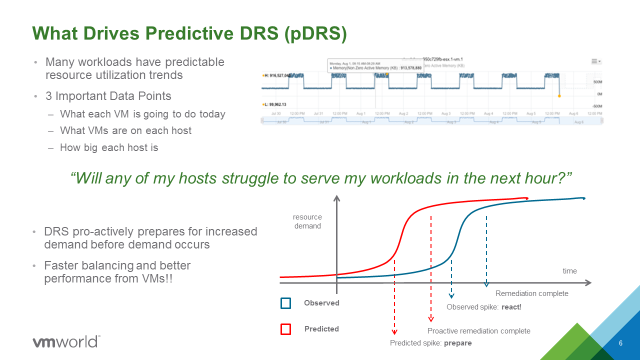
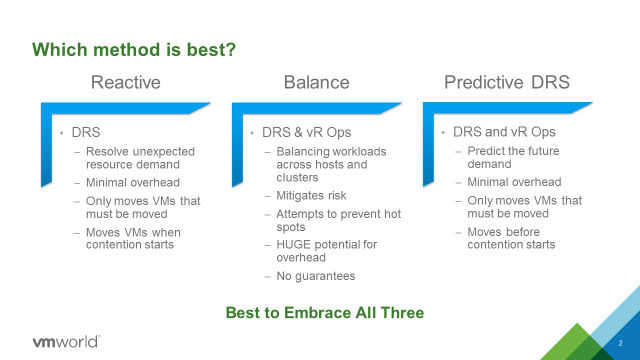
 Automation tools meant to facilitate application management may get you more—or less—than you bargained for, particularly as your organization matures along its software-defined journey. Underlying approaches to automation vary widely and not just because, obviously, different vendor’s solutions differ. There’s that, of course, and you already know that even two relatively ‘apples to apples’ solutions can perform differently in the same production environment for any number of reasons. But there’s more: using third party automation tools may introduce a level of risk into your application management architecture that wouldn’t otherwise exist. Worse: sometimes the downside takes a while to understand, by which time you could have a problem on your hands worse than the one the tool was purchased to solve!
Automation tools meant to facilitate application management may get you more—or less—than you bargained for, particularly as your organization matures along its software-defined journey. Underlying approaches to automation vary widely and not just because, obviously, different vendor’s solutions differ. There’s that, of course, and you already know that even two relatively ‘apples to apples’ solutions can perform differently in the same production environment for any number of reasons. But there’s more: using third party automation tools may introduce a level of risk into your application management architecture that wouldn’t otherwise exist. Worse: sometimes the downside takes a while to understand, by which time you could have a problem on your hands worse than the one the tool was purchased to solve!

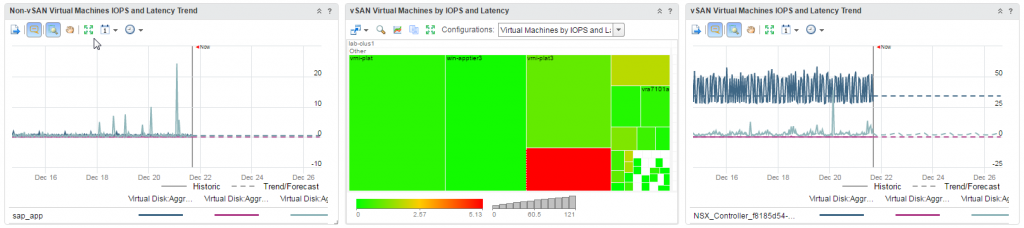
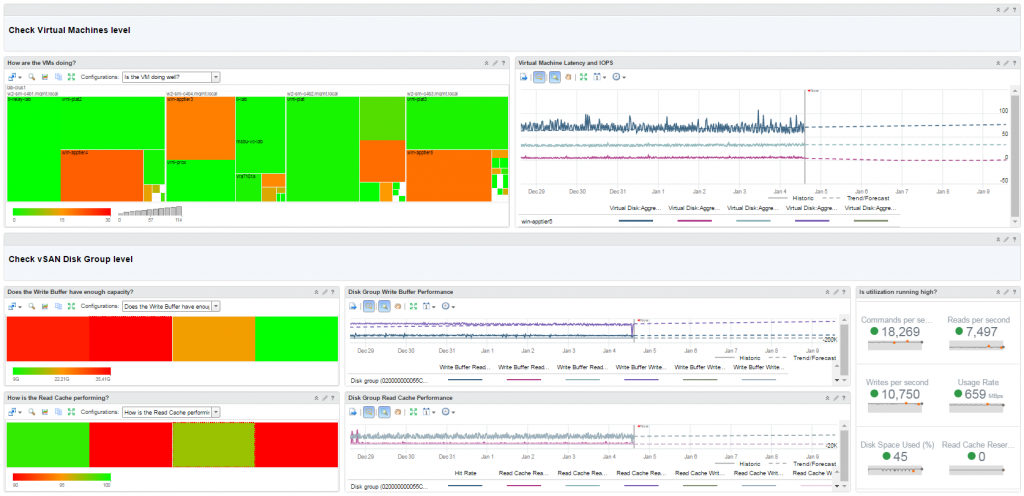









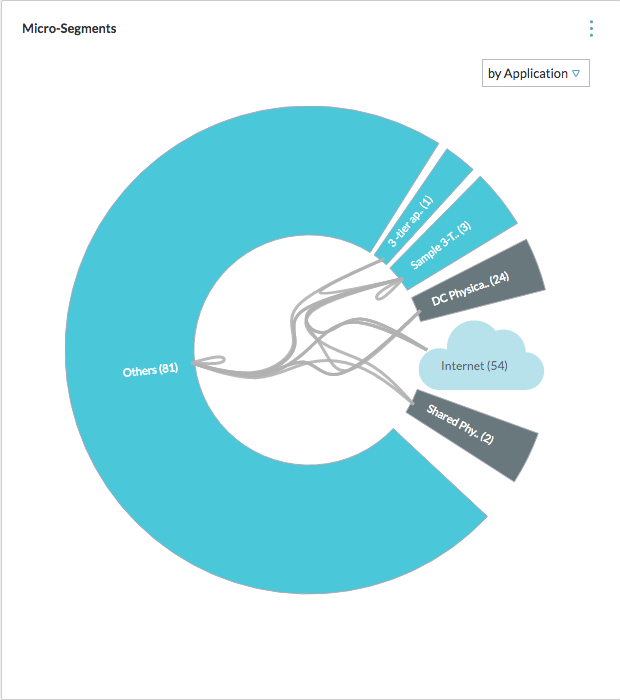 How VMware IT Leverages vRealize Network Insight
How VMware IT Leverages vRealize Network Insight